Shyamgopal Karthik
I am a researcher at Genmo working on world models. Previously, I did my PhD at the University of Tübingen broadly working on problems at the intersection of Vision and Language. I've especially enjoyed working on post-training diffusion models in the past couple of years and am excited to improve the controllability of these models in the coming years.
Before this, I completed my Bachelor's and Master's degree from the International Institute of Information Technology, Hyderabad, where I worked with Prof. Vineet Gandhi on a variety of computer vision problems.
I've also done internships at Snap Research and Naver Labs Europe, where I developed better preference optimization methods for text-to-image models and self-supervised learning methods for learning from noisy and imbalanced data.
In a previous life, I used to be a terrible chess player.

News
- 18 September 2025. HyperNoise and SAEs for VLMs were accepted at NeurIPS 2025!
- 1 July 2025. Joined Genmo as a researcher!
- 25 June 2025. RankDPO was accepted at ICCV 2025!
- 23 June 2025. Defended my PhD thesis!
- 27 September 2024. ReNO was accepted at NeurIPS 2024!
- 27 September 2024. EgoCVR was accepted at ECCV 2024!
- 15 April 2024. Started my internship with Snap at Santa Monica.
- 15 January 2024. CIReVL was accepted at ICLR 2024!
Selected Publications
Generative Models

It's Never Too Late: Noise Optimization for Collapse Recovery in Trained Diffusion Models
paper Project PageGoing along with my favourite topic of test-time scaling through noise optimization for diffusion models, we tried to implement noise optimization to increase the diversity of generated samples. Unsurprisingly (as I've come to see), the method worked really well. However, we found interesting insights through this process. First, that the eigenvalues of the pairwise similarity matrix, rather than the raw similarities, are the more natural and effective quantity to optimize for diversity. Second, that analyzing the frequency characteristics of the initial noise shows that alternative initializations with different frequency profiles can improve both optimization and search.
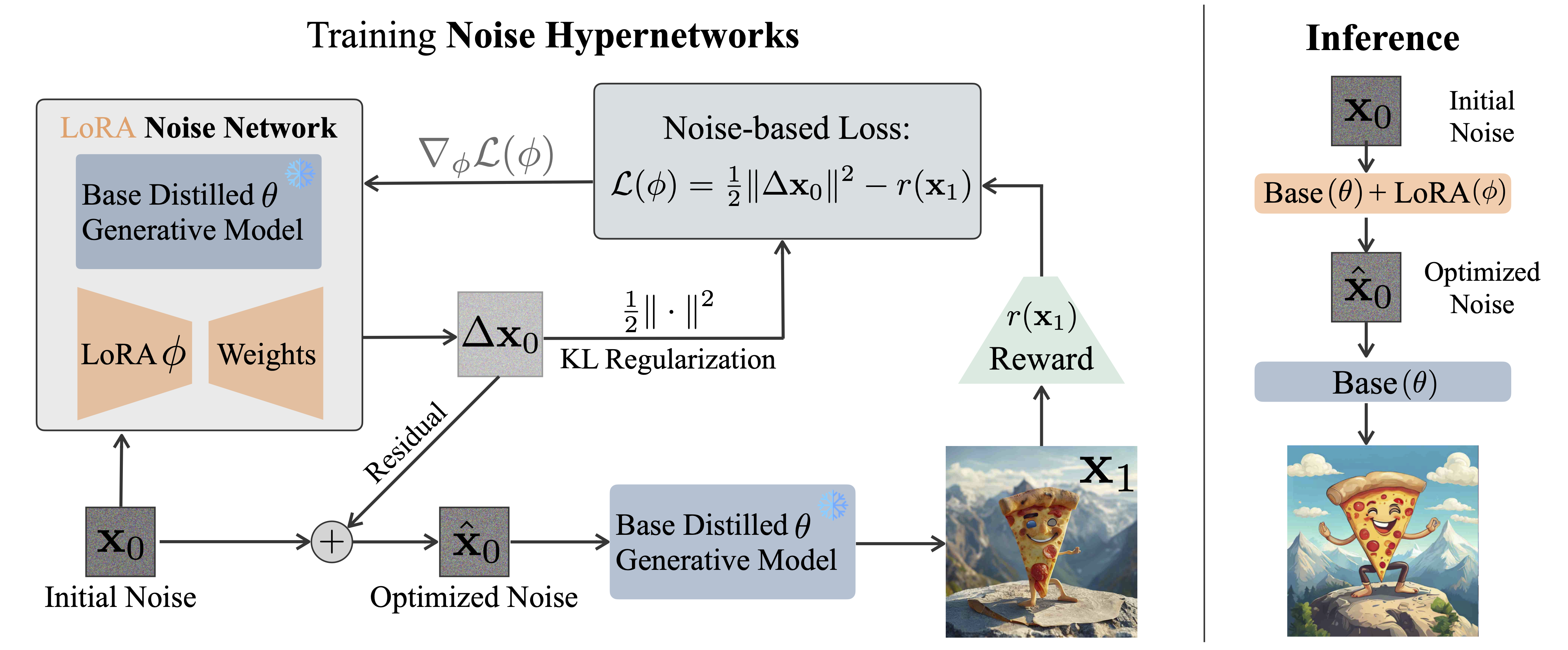
Noise Hypernetworks: Amortizing Test-Time Compute in Diffusion Models
paper code Project PageTest-time scaling had become ubiquitous in text-to-image models (among other things due to our work). However, we found a neat way to explicitly post-train for the test-time noise optimization objective by training a "hypernetwork" that is optimized to predict the optimal initial noise. This gave neat improvements even on large models like FLUX, but also gives a neat formulation for reward optimization with distilled models.

Scalable Ranked Preference Optimization for Text-to-Image Generation
paper Project PageWhile ReNO did an amazing job at improving the quality of text-to-image models, this came with an increased runtime. As a result, we were looking at DPO based techniques to improve the quality of text-to-image models. Turns out, the biggest bottleneck with applying DPO on these models is that public datasets for these tasks aren't of great quality. To address this issue, we generated and labelled a new preference dataset using newer text-to-image models and off-the-shelf reward models. This also allowed us to collect preference rankings and develop a nice ranking based objective to improve upon the standard DPO objective.
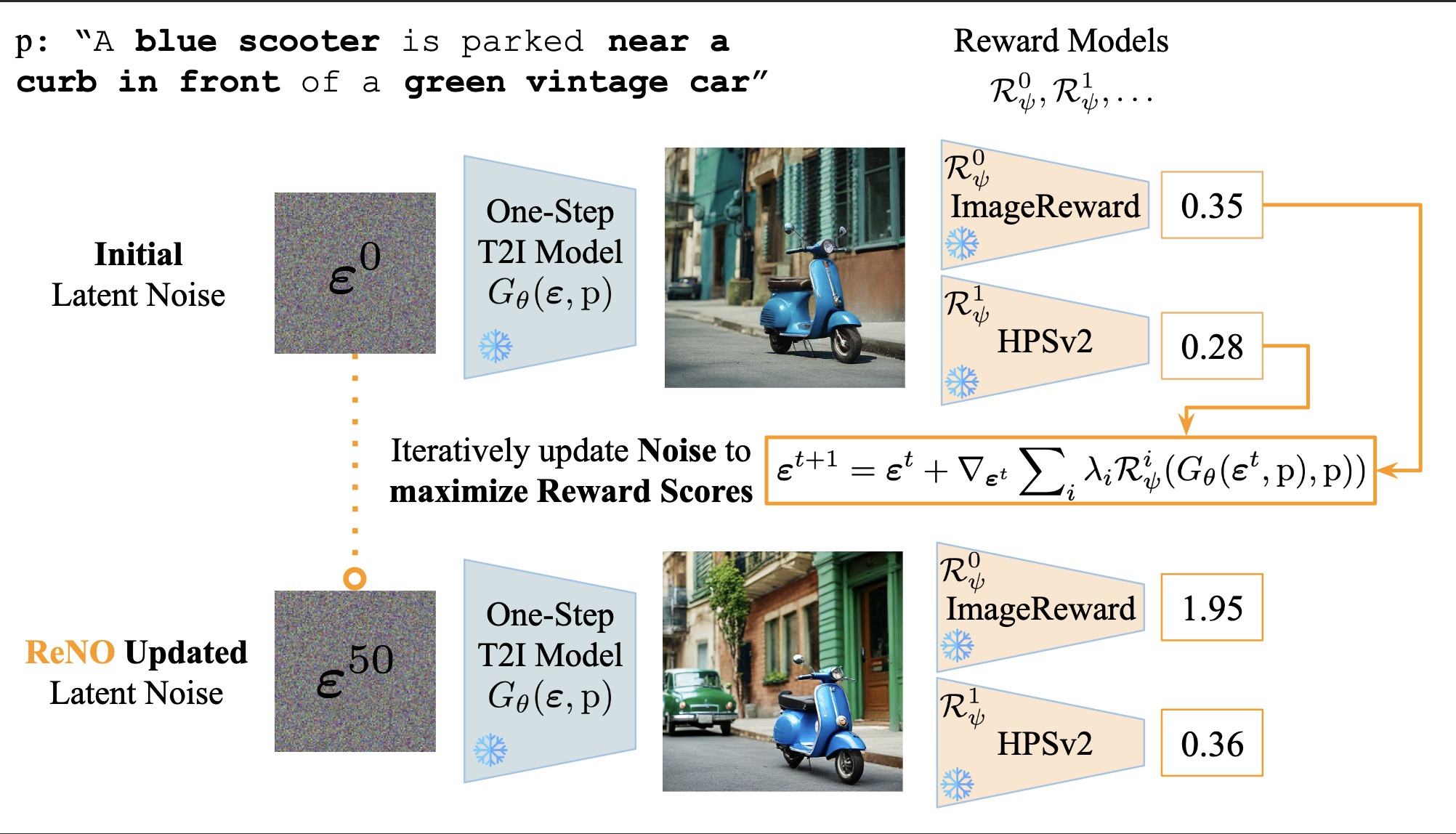
ReNO: Enhancing One-step Text-to-Image Models through Reward-based Noise Optimization
paper code demoWe knew that best-of-n sampling with a reward model was already an extremely strong baseline. However, could we go one-step further and optimize the initial noise to improve this further? This problem stumped us for a long while since backprop through the whole diffusion process was expensive and had exploding gradients. We finally found the solution with one-step models! However, would the one-step models be good enough to work with? Turns out that optimizing the noise of one-step text-to-image models could give us results that were competitive with proprietary closed source models that were 10x larger! This also culminated a fruitful 1.5 year journey for me of trying my best to find interesting research directions without updating a single parameter of any model.
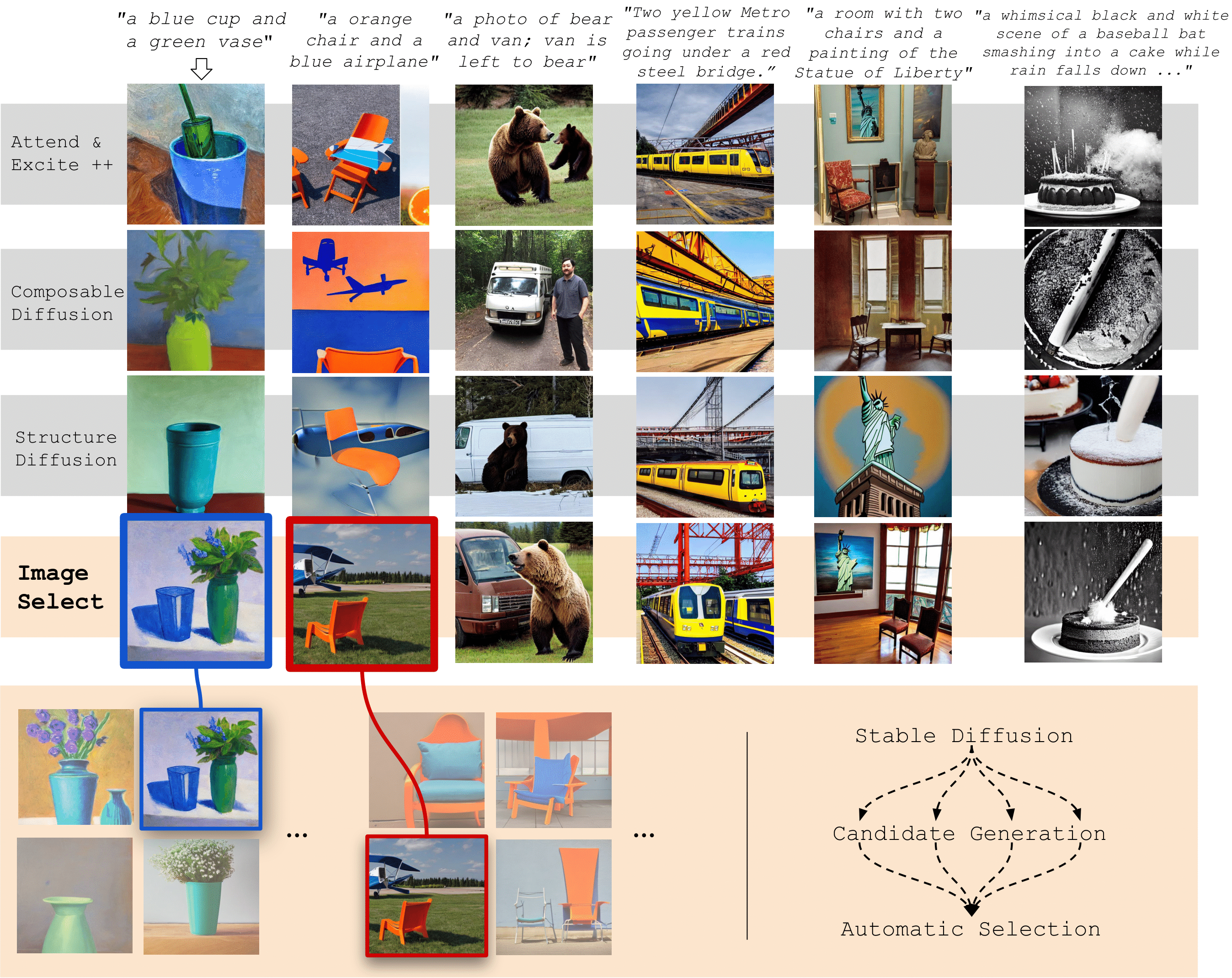
If at First You Don't Succeed, Try, Try Again: Faithful Diffusion-based Text-to-Image Generation by Selection
paper codeThis paper started my journey into text-to-image generation. The main challenge we had was that Stable Diffusion models were doing a decent job at generating high-quality images, but there were tons of issues in closely following the prompt. While there were several methods proposed especially focusing on the attention maps during inference, we realized that best-of-n sampling with a human-preference reward model went a long way in improving the results. While this was quite trivial in some ways, it set the stage for us to continue exploring the effectiveness of reward models and the effect of the seed in image generation.
Compositionality and VLMs
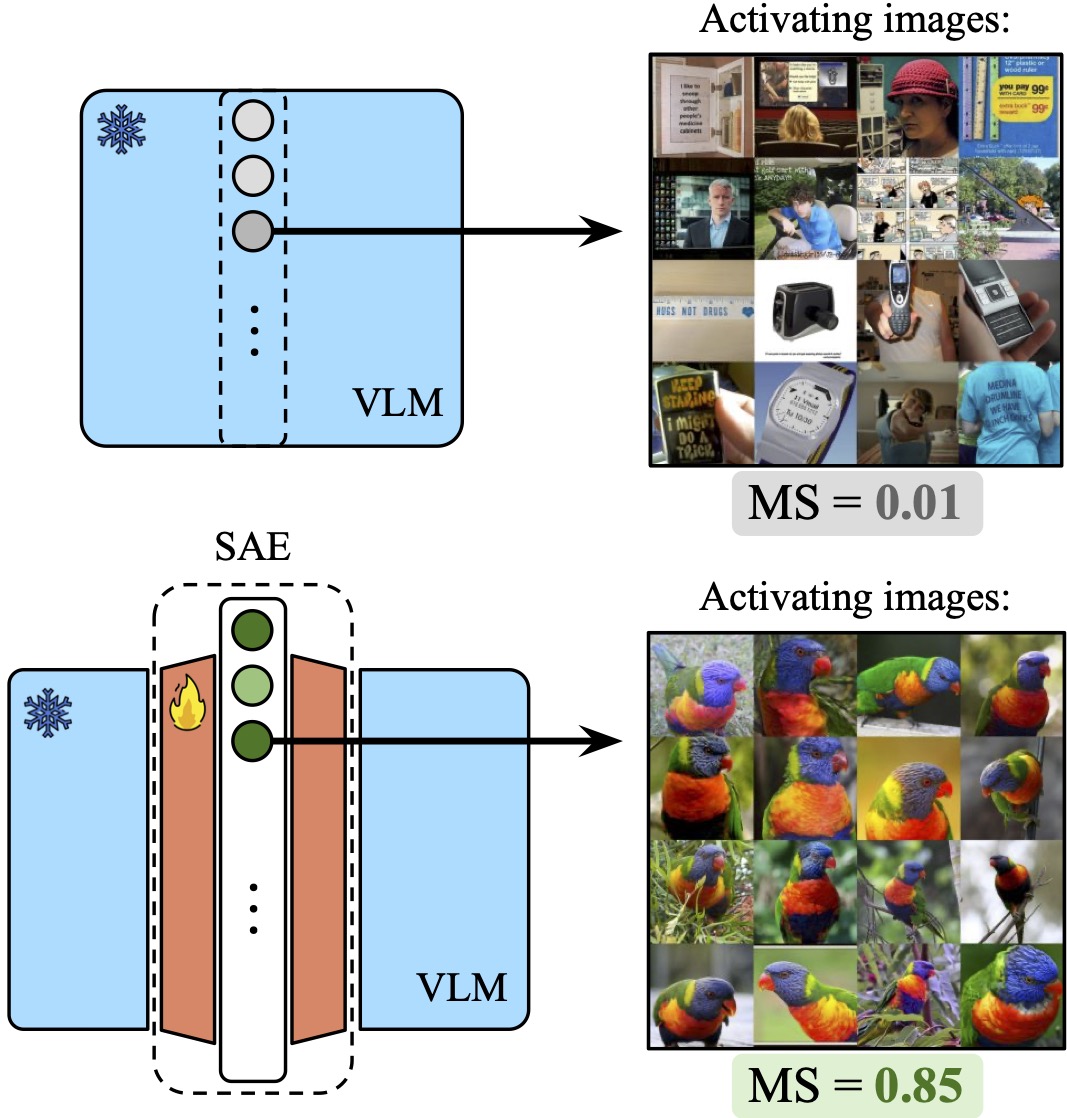
Sparse Autoencoders Learn Monosemantic Features in Vision-Language Models
paper codeThis was an illuminating exploration into mechanistic interpretability and sparse Autoencoders for me. Being able to steer multimodal LLMs with just an SAE on the vision encoder without touching the language decoder in an unsupervised manner was an especially impressive result. However, as people are finding out, SAEs (much like other interpretability methods) don't seem to be the panacea for the difficult problems of safety and controllability.
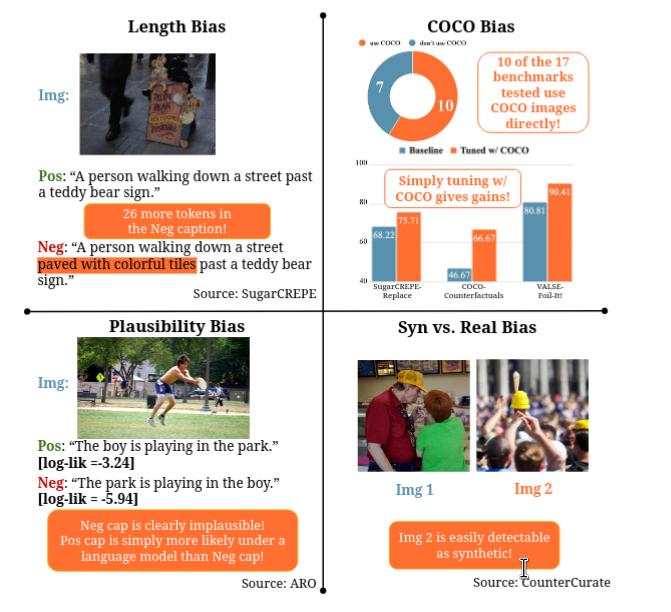
A Good CREPE needs more than just Sugar: Investigating Biases in Compositional Vision-Language Benchmarks
paperAlong with Vishaal and Mehdi, we had noticed that VLM benchmarks had a ton of issues, especially the ones focusing on fine-grained, compositional tasks. This paper was an opportunity for us to show the bitter lesson of vision-language benchmarks, where blind baselines and heuristics outperform VLMs in several cases, and fixing these benchmarks isn't too straightforward either. A few months after putting this paper out, we found out similar issues with the benchmarks in Cambrian-S too.
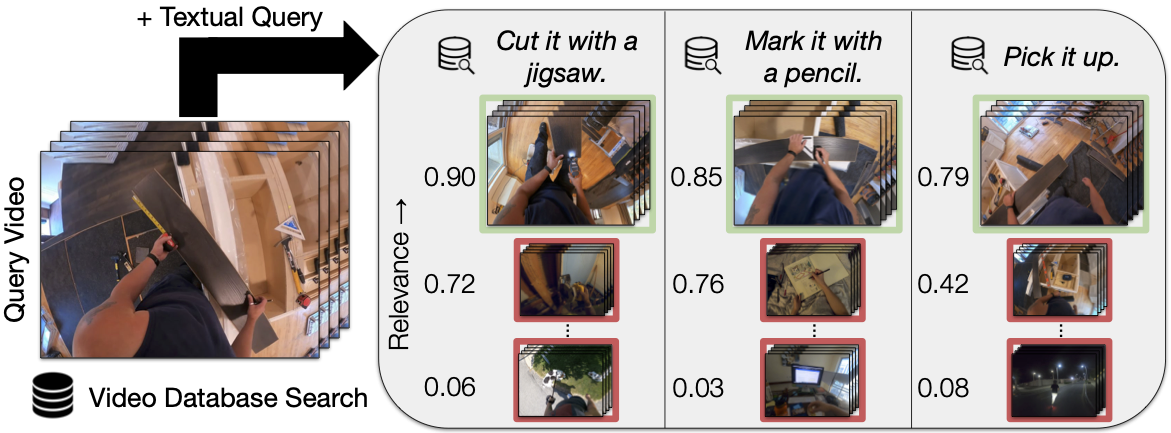
EgoCVR: An Egocentric Benchmark for Fine-Grained Composed Video Retrieval
paper codeBuilding on our previous work, we were keen on exploring Composed Video Retrieval. The biggest issue was that the existing benchmark (WebVid-CoVR) was focused excessively on images and did not really require the whole video to solve the task. To address this issue, we spent a lot of time manually curating a nice evaluation set from Ego4D which eventually turned out into a very nice benchmark. CIReVL adapted for videos also turned out to be a very nice training-free method that was competitive with methods training on millions of videos!
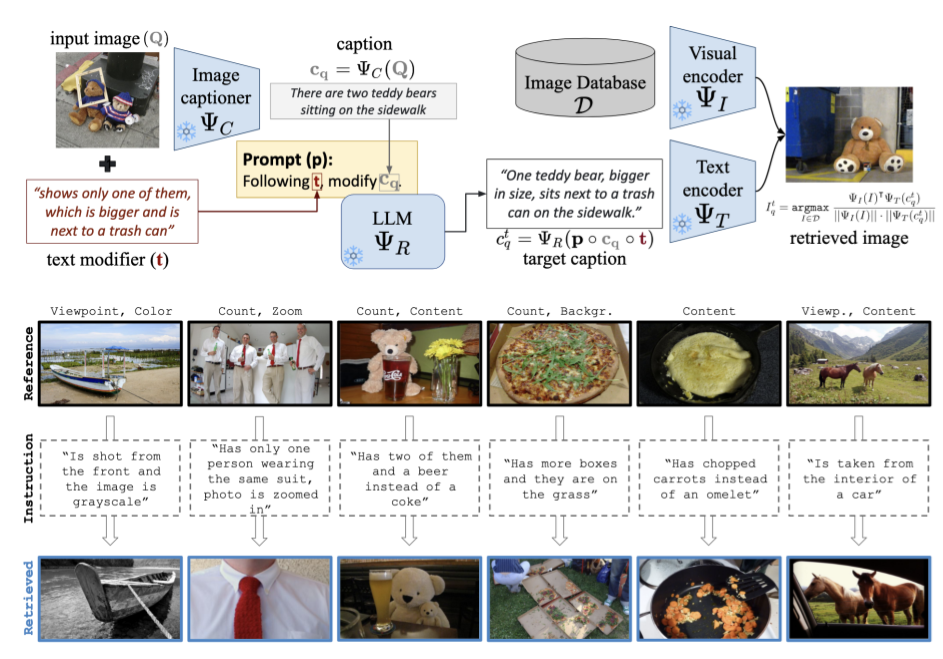
Vision-by-Language for Training-Free Compositional Image Retrieval
paper codeWe started off looking at Composed Image Retrieval task where we have a query image and textual instruction that modified the query. Popular methods for this task were trained similar to textual inversion methods and predicted a "pseudo-token" for the query image. Our immediate instinct was that using an off-the-shelf captioning model must provide a stronger and more interpretable signal than these trained pseudo-token methods. Therefore, our "vision-by-language" method was just to caption an image, reformulate the caption based on the textual instruction and retrieve images based on the reformulated caption. Not only was this method more interpretable and training-free, it also allowed us to double the state-of-the-art performance on some popular benchmarks.
Representation Learning
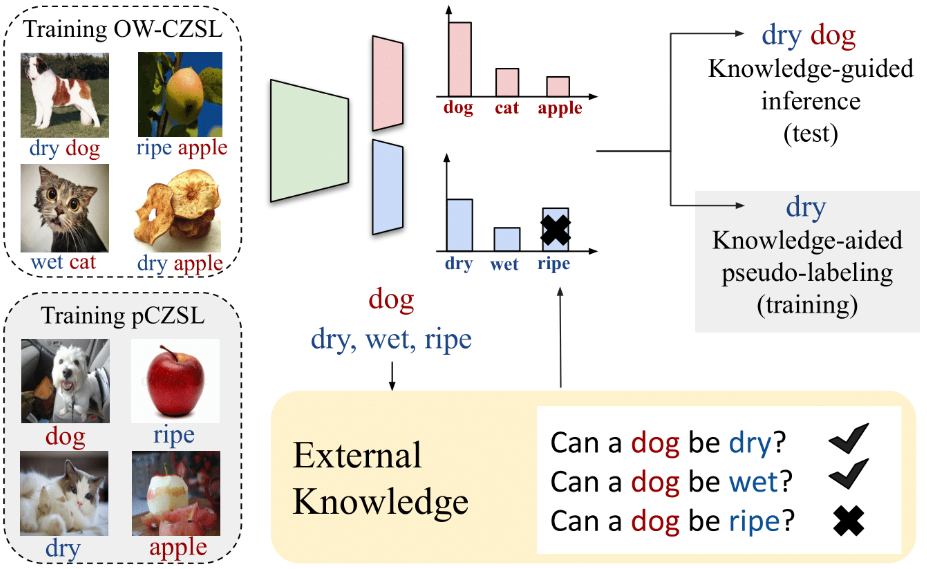
KG-SP: Knowledge Guided Simple Primitives for Open World Compositional Zero-Shot Learning
paper codeIn this work, we looked at the problem of Compositional Zero-Shot Learning, where the goal is to predict (attribute, object) labels for an image, and generalize to unseen (attribute, object) pairs. Recent methods had tried to model attributes and objects jointly using a variety of ideas. Here, we show that predicting attributes and objects independently can work quite well for this task. Additionally, we show how a knowledge-base can be incorporated to improve the performance of the model at inference. Finally, we introduce a new partially labeled setting where we show how we can train our model in the absence of compositional labels.
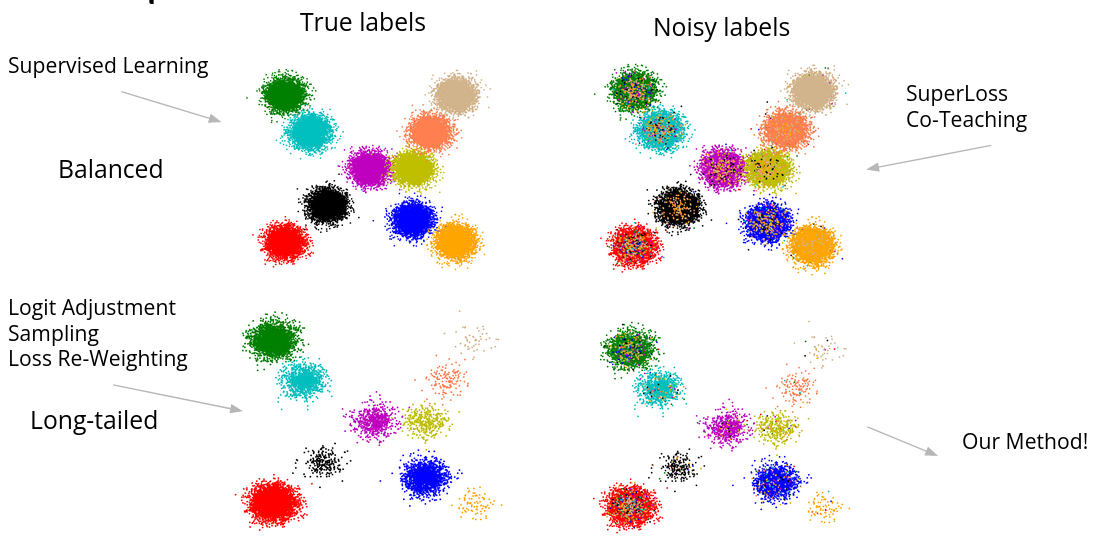
Learning from Long-Tailed Data with Noisy Labels
paperThis paper started off as a journey towards developing methods that are robust to both label noise and long-tailed class distributions. Methods tailored for one of these challenges collapsed when the other challenge was introduced. In the end, it turned out that vanilla self-supervised training went a long way in learning representations that were robust to both label noise and long-tailed distributions.
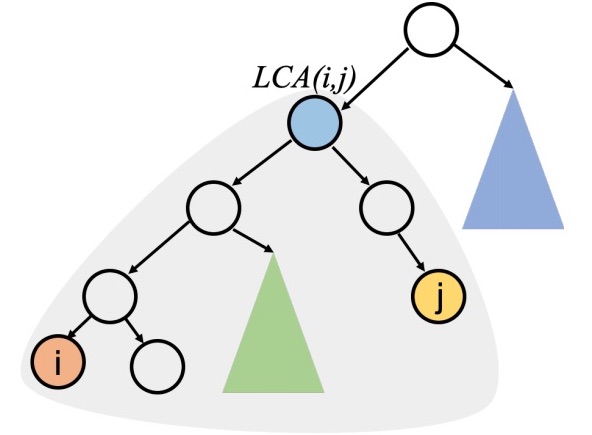
No Cost Likelihood Manipulation at Test Time for Making Better Mistakes in Deep Networks
paper codeThe main motivation behind this work was to see if we could reduce the severity of mistakes in a classification setting. To do this, we make use of label hierarchies which are readily available through taxonomies like WordNet. For our method, we show that a simple algorithm from Duda and Hart's Pattern Recognition textbook way back in 1973 can be effectively used in a post-hoc manner while retaining the calibration of the base model.
Simple Unsupervised Multi-Object Tracking
paperWe revisited Re-Identification models that were widely used in Multi-Object Tracking algorithms. In various trackers, this is often the only component that requires video level supervision. Our insight was that we could train a ReID model using pseudo-labels generated from a Kalman filter based tracker in a self-supervised fashion. The resulting ReID model can be used as a drop-in replacement to the supervised ReID models used in trackers. Alternatively, using these ReID features as a post-processing step in trackers that don't use a ReID model can reduce the number of ID Switches by 67%. In hindsight, I hope this was useful in motivating some works later on which strengthened the traditional tracking-by-detection paradigm.